用BeautifulSoup提取网页信息实例
用python提取网页中需要的内容时,免不了要处理html文档。
遥想当年,扒教务网的考试成绩,是用的正则表达式处理:
pattern = re.compile('<tr class="odd".*?>.*?<td.*?>.*?</td>.*?<td.*?>.*?</td>.*?<td.*?>(.*?)</td>.*?<td.*?>.*?</td>.*?<td.*?>(.*?)</td>.*?<td.*?>(.*?)</td>.*?<td.*?>.*?<p align="center">(.*?) ', re.S)
现在再看这段代码,整个人都不好了......

BeautifulSoup
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
安装
依然是用pip:
pip install beautifulsoup4另外还要装个解析器:
pip install lxml装好后,在交互环境引入下,不报错就ok
from bs4 import BeautifulSoup创建对象
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html, "lxml")
!这里的"lxml"是指定编译器,不指定的话,运行时会出现警告信息。
还可以用本地的html文档:
soup = BeautifulSoup(open('index.html'), "lxml")
比较好用的方法是先用requests库获取到html文本,再交给BeautifulSoup处理:
html = requests.get(url).text
soup = BeautifulSoup(html, "lxml")
遍历文档
遍历文档最重要的方法是find_all()和find()。使用这两个方法就基本可以解决问题了。
find()
find获取到找到的第一个节点,直接返回结果
e.g.要在html文档里面定位到这样一段无序列表:
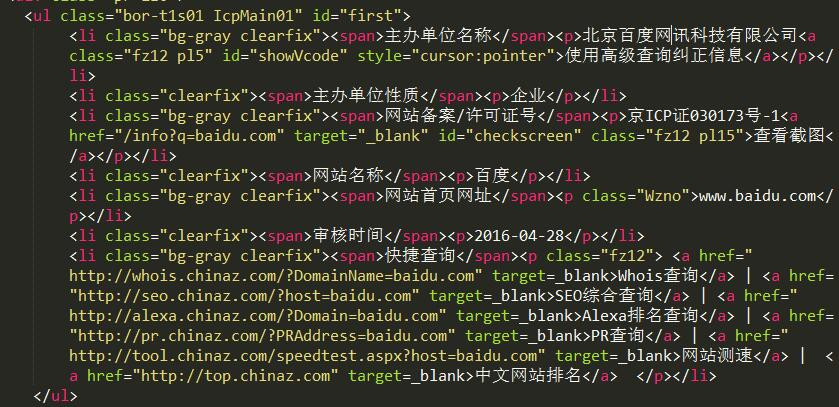
context = soup.find('ul', class_='bor-t1s01 IcpMain01')
- "ul"对应
name属性 - "class_='bor-t1s01 IcpMain01'"对应
attrs(由于class是python关键字,所以用class_代替)
find_all()
find_all返回一个列表,对应找到的所有节点。
继续上面的html片段,需要找到所有<li>标签里的内容,这时就要find_all()了。
context_ = context.find_all(class_="clearfix")
获取文本
接上边的内容,用context_[0]定位到如下的html片段:

要获取北京百度网讯科技有限公司这段文本:
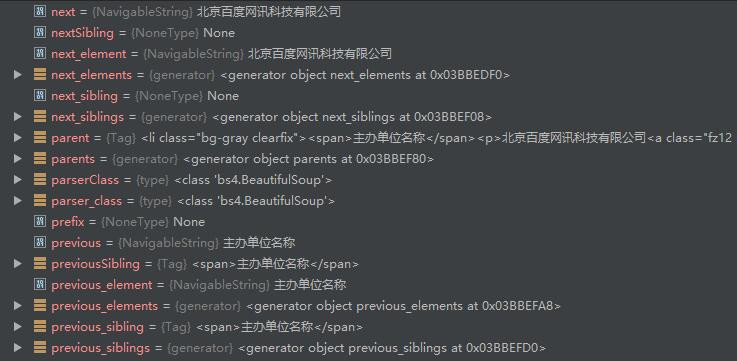
user = context_[0].find('p').next
find('p')定位到<p>标签next定位到<p>标签的下一个节点,就是我们要的文本了- 如果再调用一次next方法,得到的就是
<a class="fz12 pl5" id="showVcode" style="cursor:pointer">使用高级查询纠正信息</a>
如果拿到某个节点后不知道怎么去获取文本,开启了懵逼模式,那么一个好办法是打开pycharm的debug,这个节点下面的啥东西都清楚了~
end
BeautifulSoup还有很多其他的方法来处理html,比如根据css选取的select(),功能都大同小异.....大多数情况下,上述的方法应该够用了,虽然有些时候并不优雅= = ,等遇到上述方法解决不了的问题的时候,再去啃文档吧。
可以追加吗?