Scrapy爬取博客网站
Scrapy架构
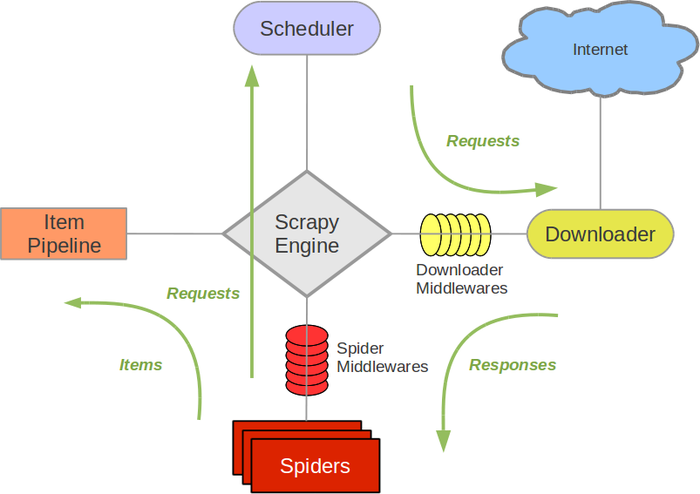
Scrapy Engine
Scrapy Engine负责控制整个数据处理的流程,和事件的触发。
Scheduler
调度程序从Scrapy Engine接受请求并排序列入队列,并在Scrapy Engine发出请求后返还给他们。
Downloader
下载器的主要职责是抓取网页并将网页内容返还给Spider。
Spiders
Spiders是有Scrapy用户自己定义用来解析网页并抓取制定URL返回的内容的类,每个Spider都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
Item Pipeline
Item Pipeline的主要责任是负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被Spider解析后,将被发送到Item Pipeline,并经过几个特定的次序处理数据。每个Item Pipeline的组件都是有一个简单的方法组成的Python类。他们获取了项目并执行他们的方法,同时他们还需要确定的是是否需要在Item Pipeline中继续执行下一步或是直接丢弃掉不处理。
Downloader middlewares
Downloader middlewares是位于Scrapy Engine和下载器之间的钩子框架,主要是处理Scrapy Engine与下载器之间的请求及响应。它提供了一个自定义的代码的方式来拓展Scrapy的功能。Downloader middlewares是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
Spider middlewares
Spider middlewares是介于Scrapy Engine和Spider之间的钩子框架,主要工作是处理Spider的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy的功能。Spider middlewares是一个挂接到Scrapy的Spider处理机制的框架,你可以插入自定义的代码来处理发送给Spider的请求和返回Spider获取的响应内容和项目。
Scheduler middlewares
Scheduler middlewares是介于Scrapy Engine和调度之间的中间件,主要工作是处从Scrapy Engine发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
Scrapy处理流程
- Engine打开一个域名,让Spider处理这个域名,并让Spider获取第一个爬取的URL。
- Engine从Spider那获取第一个需要爬取的URL,然后作为请求在Scheduler中进行调度。
- Engine从Scheduler那获取接下来进行爬取的页面。
- Scheduler将下一个爬取的URL返回给Engine,Engine将他们通过Downloader middlewares发送到Downloader。
- 当网页被Downloader下载完成以后,响应内容通过Downloader middlewares被发送到Engine。
- Engine收到Downloader的响应并将它通过Spider middlewares发送到Spider进行处理。
- Spider处理响应并返回爬取到的数据,然后给Engine发送新的请求。
- Engine将抓取到的数据交给Item Pipeline,并向Scheduler发送请求。
- 系统重复第二部后面的操作,直到Scheduler中没有请求,然后断开Engine与域之间的联系。
Scrapy项目结构
通过如下代码可以新建scrapy项目:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com文件结构:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
└── spider.py
一个普通的scrapy项目,主要需要编写items.py,pipelines.py,spider.py三个文件。
items.py
定义要爬取的字段
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
spider.py
定义爬取规则和爬取路径
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"http://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
pipelines.py
将抓取的数据存入数据库
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
setting.py
在配置文件里添加一些基本配置
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
这时就可以运行爬虫了:
$ scrapy crawl stack通用型博客爬虫
针对每一个网站都创建一个爬虫项目实在太繁琐,但每个爬虫的爬取路径等信息都不同,不能简单的把一个项目进行复用 。在参考了神箭手后,写出了一个功能简单的通用爬虫。
能够爬取的网站必须满足:
- 可以分页读取历史文章
- 通过feed或者atom进行rss更新
设计思路是将每一个网站特有的信息保存到数据库,运行某个网站的爬虫时,再将它的信息从数据库读取出来,放到相应的代码中。
所以需要建立两个数据表:
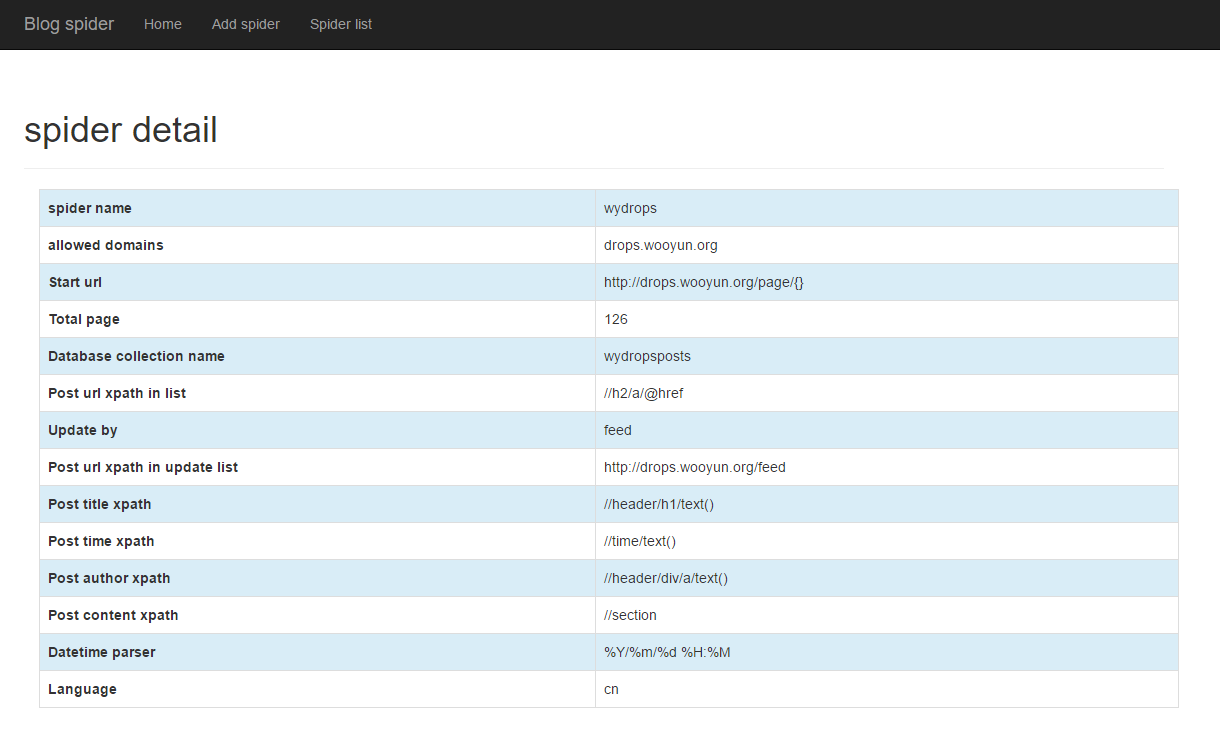
第一个存放网站的爬虫配置信息
/* 1 */
{
"_id" : ObjectId("57621e7a9d60312fe4f2ba65"),
"url_page" : 126,
"site_name" : "wydrops",
"col_name" : "wydropsposts",
"post_time_xpath" : "//time/text()",
"update_list_url" : "http://drops.wooyun.org/feed",
"post_title_xpath" : "//header/h1/text()",
"post_content_xpath" : "//section",
"allowed_domains" : "drops.wooyun.org",
"language" : "cn",
"post_author_xpath" : "//header/div/a/text()",
"datetime_parser" : "%Y/%m/%d %H:%M",
"list_post_url_xpath" : "//h2/a/@href",
"start_url" : "http://drops.wooyun.org/page/{}",
"update_by" : "feed"
}
第二张存放每次爬取的更新时间
{
"_id" : ObjectId("576221009d60311204a608a5"),
"site_name" : "wydrops",
"title" : "逆向浅析常见病毒的注入方式系列之一-----WriteProcessMemory",
"url" : "http://drops.wooyun.org/feed",
"timestamp" : ISODate("2016-06-16T02:44:18.000Z"),
"last_updated_at" : ISODate("2016-06-16T03:46:43.671Z")
}
文件结构:
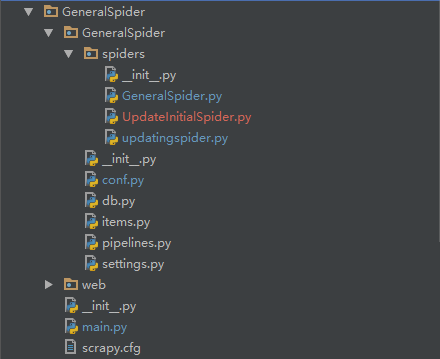
其中db.py用来建立数据库连接,conf.py从数据库中读取网站的配置信息,web文件夹存放flask应用,作为项目的web端。
GeneralSpider.py解析文章列表,根据页码爬取历史文章。
# -*- coding=utf8 -*-
from datetime import datetime
from scrapy.spiders import Spider
from scrapy.http import Request
from ..items import GeneralspiderItem
from ..conf import CONF
class GeneralSpider(Spider):
name = 'GeneralSpider'
allowed_domains = CONF['allowed_domains']
start_urls = [
CONF['start_url'].format(i) for i in range(1, CONF['url_page'] + 1)
]
def parse(self, response):
urls = response.xpath(CONF['list_post_url_xpath']).extract()
for url in urls:
if not url.startswith("http"):
url = "http://" + CONF['allowed_domains'] + url
request = Request(url=url, callback=self.parse_post, dont_filter=True)
yield request
def parse_post(self, response):
item = GeneralspiderItem()
item['url'] = response.url
item['title'] = response.xpath(CONF['post_title_xpath']).extract()[0].strip()
try:
item['author'] = response.xpath(CONF['post_author_xpath']).extract()[0].strip()
except:
pass
try:
published_at = response.xpath(CONF['post_time_xpath']).extract()[0].strip()
item['published_at'] = datetime.strptime(published_at, CONF['datetime_parser'])
except:
pass
item['crawled_at'] = datetime.now()
item['content'] = response.xpath(CONF['post_content_xpath']).extract()[0] # 可能需要转义HTML
yield item
UpdateInitialSpider.py在爬取历史文章后运行,作用是初始化更新表。
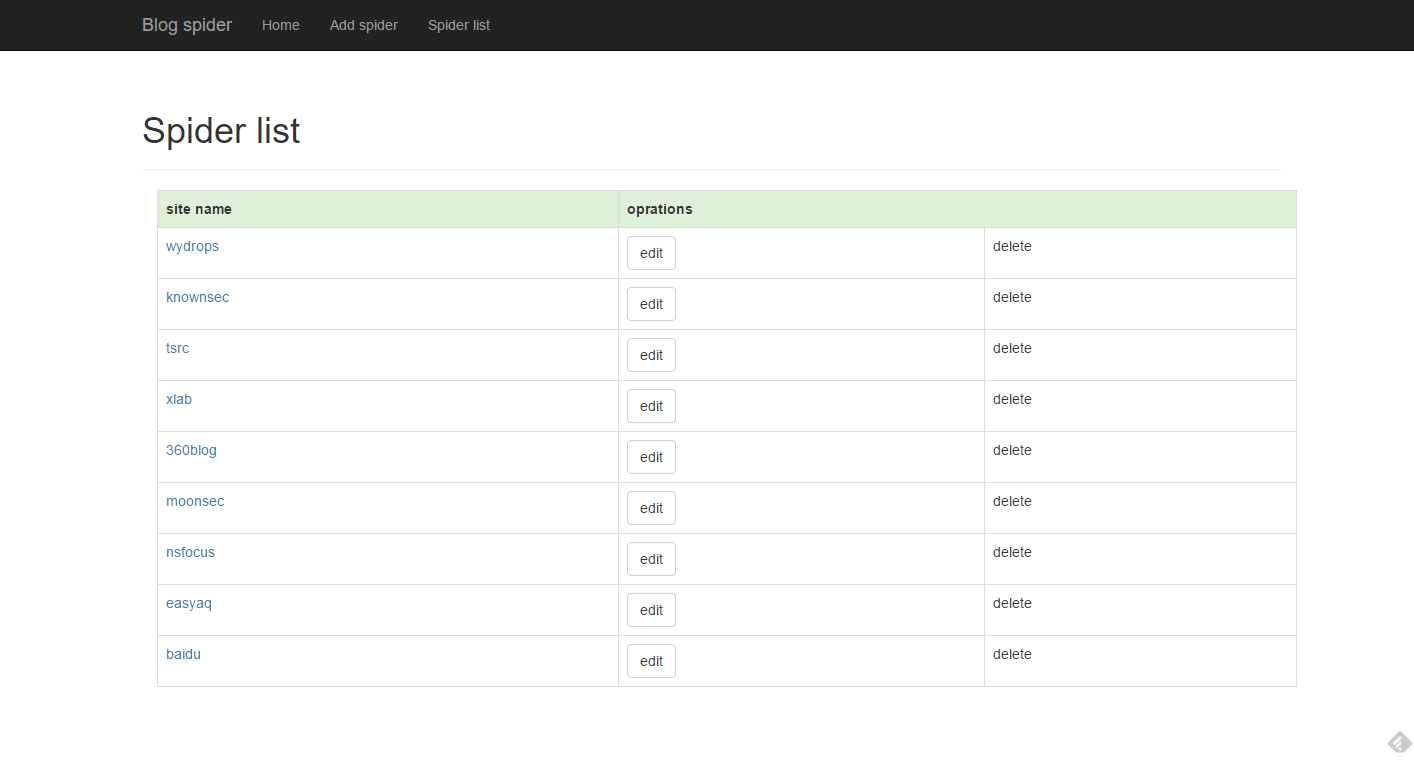
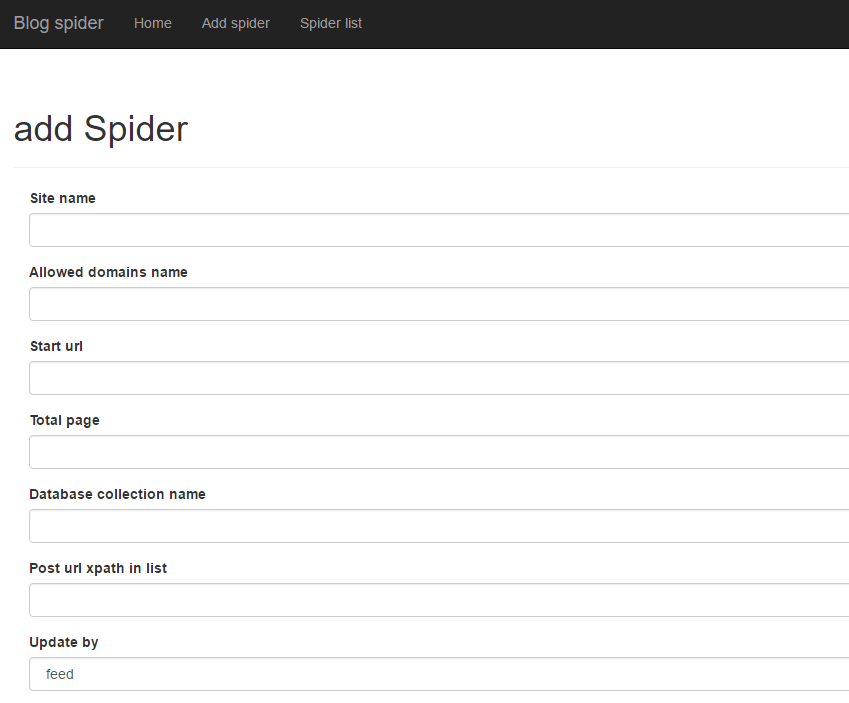
web端效果:
todo
- 优化通用爬虫的兼容性(phantomjs+selenium)
- 学习celery分布式任务队列,让爬虫通过web端的请求启动,并把scrapy任务通过celery异步执行。