phantomjs爬虫服务化
最近发现部署爬虫的VPS上MongoDB数据库老是崩,检查半天才发现是内存耗尽导致。top查看内存使用情况时被吓了一跳,密密麻麻的phantomjs进程几乎填满了内存。
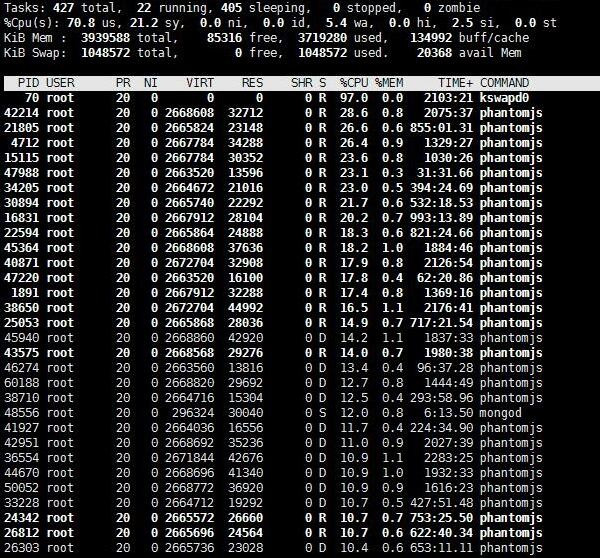
这些phantomjs进程都是由定时爬虫的selenium启动的,但是没有被selenium关闭。尝试了stackoverflow上的各种方法,都不奏效。查看selenium源码,发现它是利用Ghost Driver通过The WebDriver Wire Protocol与phantomjs通信。这里也就相当于phantomjs是一个web服务器,selenium通过api对它各种操作。比如:selenium关闭phantomjs的代码:
# ~/selenium/webdriver/common/server.py line115
def send_remote_shutdown_command(self):
......
try:
url_request.urlopen("%s/shutdown" % self.service_url)
except URLError:
return
count = 0
while self.is_connectable():
if count == 30:
break
count += 1
time.sleep(1)
看到这里,似乎有一个比为什么没有关闭phantomjs进程更值得考虑的问题了,为什么要关闭它呢?
driver = webdriver.PhantomJS(executable_path='/usr/local/bin/phantomjs')
try:
driver.get(request.url)
time.sleep(1)
content = driver.page_source.encode('utf-8')
finally:
driver.quit()
每当有一个待爬取的url进到这段程序时,就先创建一个phantomjs进程(实际是个WebDriver),用完再将它关闭。随着url源源不断的到来,这些WebDriver开了关,关了又开。怪不得速度慢的一逼。
如果不用每次都开启关闭phantomjs,让它作为一个web服务一直运行,把需要爬取的url作为请求数据交给它,爬取好后把页面代码作为响应返回,感觉这样即省了时间,又避免了之前的问题。
Google一下发现果然可行!phantomjs本来就支持Web Server Module.
PhantomJS script can start a web server. This is intended for ease of communication between PhantomJS scripts and the outside world and is not recommended for use as a general production server. There is currently a limit of 10 concurrent requests; any other requests will be queued up.
这种服务不能作为常规的web服务器,最多能处理10个并发请求,其余的请求会被挂起。并发虽小,但作为爬虫服务器来说也勉强够用,挂起也比每次开关服务器强啊。
phantomjs拿到待爬取url后,使用Web Page Module就可以得到渲染好的页面了。
// phantom_server.js
var webserver = require("webserver");
var server = webserver.create();
var service = server.listen(8888, function(request, response) {
var url = request.post["data"];
console.log(url);
var webPage = require("webpage");
var page = webPage.create();
page.settings.userAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36";
page.settings.resourceTimeout = 5000;
page.open(url, function start(status) {
if (status == "success") {
window.setTimeout(function() {
content = page.content;
response.statusCode = 200;
response.write(content);
response.close();
page.close()
}, 1000)
} else {
response.statusCode = 500;
response.write("error");
response.close();
page.close()
}
})
});
上面各种接口的使用在文档中写的很详细,不用再多说了。启动服务器:phantomjs phantom_server.js
这时再用python请求服务器就很轻松了:
import requests
from requests.exceptions import RequestException
server_url="http://localhost:8888"
try:
res = requests.post(server_url, data={'data':url}, timeout=10)
except RequestException:
pass
if res.status_code == 200:
content = res.content
用上面的代码替换掉之前selenium的部分,整个爬虫就修改好了。用一段测试代码分别使用之前的selenium+phantomjs,和phantomjs server测了几个网站,发现效果还是挺明显的,虽然都很慢...
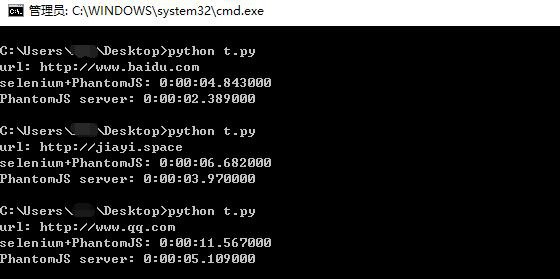
关于优化策略,可以关闭图片加载page.settings.loadImages = false;,本地缓存phantomjs serverjs --disk-cache=true,启动多个phantomjs server进行负载均衡增加并发等。
赞一个,优雅地解决了爆内存的问题。
为什么我请求的都是403?