kubernetes从入门到放弃5--(存储原理)
Kubernetes的一大特点就是无状态的容器可以在集群中的任意节点内运行或销毁,这样的自由度却给有状态的容器带来了麻烦。有状态容器产生的数据需要在容器重建之后仍能够继续使用,docker提供的目录挂载只能解决单一节点下的数据持久化,而Kubernetes要求的是在集群范围内的数据持久化,这就需要引入外部的分布式文件系统。比如GlusterFS、NFS、CephFS等....
一 PV、PVC
分布式文件系统基本都是基于API交互,所以Kubernetes需要封装这些交互细节,让容器中操作共享存储路径与其他容器路径没有区别。所以Kubernetes使用了PersistentVolume(PV)和PersistentVolumeClaim(PVC)两个资源概念。
1.1 PersistentVolume
就像Pod需要申明对Node中资源如CPU、内存的使用方式,PV则是申明对分布式文件系统中存储资源的使用方式。PV需要申明的内容主要有存储能力、访问模式、回收策略、后端存储类型等.....
用文档中的例子来看看:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /tmp
server: 172.17.0.2这里定义了一个存储能力为5G、访问模式为单次读写、回收策略为回收空间、后端为NFS的PV。
1.1.1 capacity
存储能力只需要定义为存储空间的大小
1.1.2 accessModes
访问模式分为三种:
- ReadWriteOnce 只允许单个Node拥有读写权限
- ReadOnlyMany 多个Node拥有只读权限
- ReadWriteMany 多个Node拥有读写权限
并不是所有分布式文件系统都支持这三种模式,具体的支持类型可以看看文档。
1.1.3 persistentVolumeReclaimPolicy
回收策略也包括三种:
- Retain 保留,手动处理
- Recycle 删除文件(不清除与后端存储的连接)
- Delete 断开与后端存储的连接
1.1.4 后端存储类型
PV可以支持多种存储后端,具体的类型可以看看文档。
1.2 PersistentVolumeClaims
我的理解下,PVC就是PV的选择器,PVC可以设置存储使用方式,匹配出符合条件的PV,进行绑定。
还是用文档的例子来看看:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 8Gi
storageClassName: slow
selector:
matchLabels:
release: "stable"
matchExpressions:
- {key: environment, operator: In, values: [dev]}可以看出,PVC可以通过设置与PV一样的存储调用方式来匹配PV。还可以通过selector标签选择器来匹配PV。
1.3 Pod挂载
定义好PV、PVC后,就可以在Pod中挂载了。
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: dockerfile/nginx
volumeMounts:
- mountPath: "/var/www/html"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaim
volumes通过名为myclaim的PVC匹配到相应的PV,并将PV中定义的存储资源挂载为mypd,以供容器中使用。
相应的,PV根据使用情况可能处于以下4种状态之一:
- Available 待绑定状态
- Bound 已经绑定到了PVC
- Released 绑定已解除,资源还未被回收
- Failed 回收失败
二 动态资源供应
PV、PVC模式下Pod每次使用PVC挂载存储资源之前,需要预先定义好足够的PV,这样略显麻烦。所以Kubernetes提供了动态资源供应模式,使用StorageClass资源概念,只要在StorageClass中定义好了后端存储连接,就可以根据PVC中的调用申明自动地创建PV。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssdprovisioner定义了StorageClass的后端存储类型,parameters包含连接该后端存储的参数。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: claim1
spec:
accessModes:
- ReadWriteOnce
storageClassName: fast
resources:
requests:
storage: 30Gi在PVC中,通过storageClassName: fast指定对应的StorageClass,其他的资源使用申明确定了自动创建的PV中的资源使用参数。
三 GlusterFS with Kubernetes
GlusterFS是一个开源的分布式文件系统,是Kubenetes支持的众多共享存储之一。因为自己搭建的时候用的这个,所以就单独列出来说说。
3.1 GlusterFS
GlusterFS (Gluster File System) 是一个开源的分布式文件系统。GlusterFS是Scale-Out存储解决方案Gluster的核心,具有强大的横向扩展能力,通过扩展能够支持数PB存储容量和处理数千客户端。GlusterFS基于可堆叠的用户空间设计,可为各种不同的数据负载提供优异的性能。
GlusterFS的特点包括:扩展性和高性能、高可用性、全局统一命名空间、弹性哈希算法、弹性卷管理、基于标准协议。
关于GlusterFS的介绍可以参考:GlusterFS分布式文件系统学习之 简介篇
3.2 Heketi
Heketi是GlusterFS基于RESTful API的管理端,Kubernetes、OpenStack、OpenShift这些云服务可以通过Heketi实现基于GlusterFS的动态资源供应。
3.3 基于GlusterFS的动态资源供应
在gluster的Github上有一个gluster-kubernetes项目,演示了如何轻量化地在已有的Kubernetes集群中集成基于GlusterFS的动态资源供应。
之所以说是轻量级,是因为它把GlusterFS集群作为DaemonSet部署到了集群中,Heketi也作为Service部署。
具体的部署过程可以参考Gluster-kubernetes Setup Guide。需要注意的是要预先为集群的每个节点挂载两块空磁盘,并把集群信息更新到topology.json.sample。之后使用其提供的gk-deploy可以一键部署。
之后可以通过Hello World application using GlusterFS Dynamic Provisioning看看如何在Pod中使用动态资源供应。大致的过程如下图:
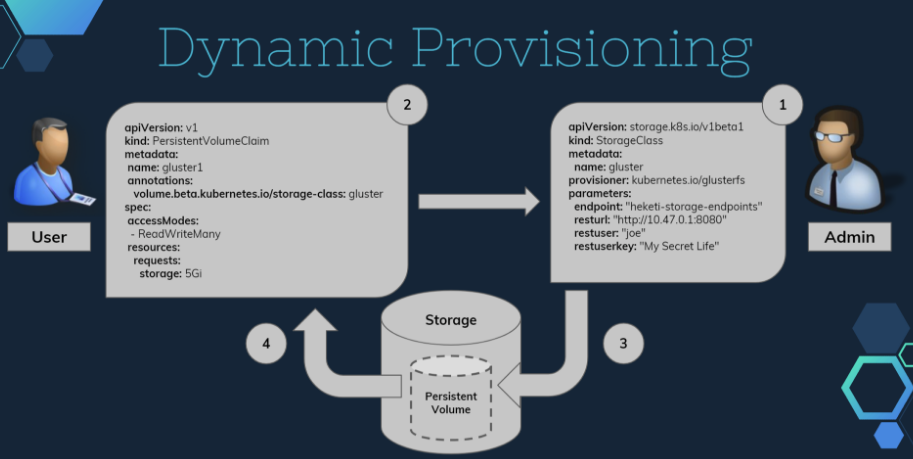
- 由管理员定义StorageClass,定义好与Heketi的连接。
- Pod通过PVC申明需要的存储资源细节。
- Heketi管理GlusterFS生成对应存储空间的PV。
- 与PVC绑定,供Pod挂载。