kubernetes从入门到放弃2--(组件架构)
上一篇主要是总结了Kubernetes对各种资源概念的抽象分类,而这一篇准备总结下Kubernetes的组件架构,看一看那些抽象出来的资源概念的背后,都是些什么程序,而他们又是怎么组合出Kubernetes的强大功能。因为还没有读过源码,自己的使用场景也有限,这里就主要总结下各种组件的功能。
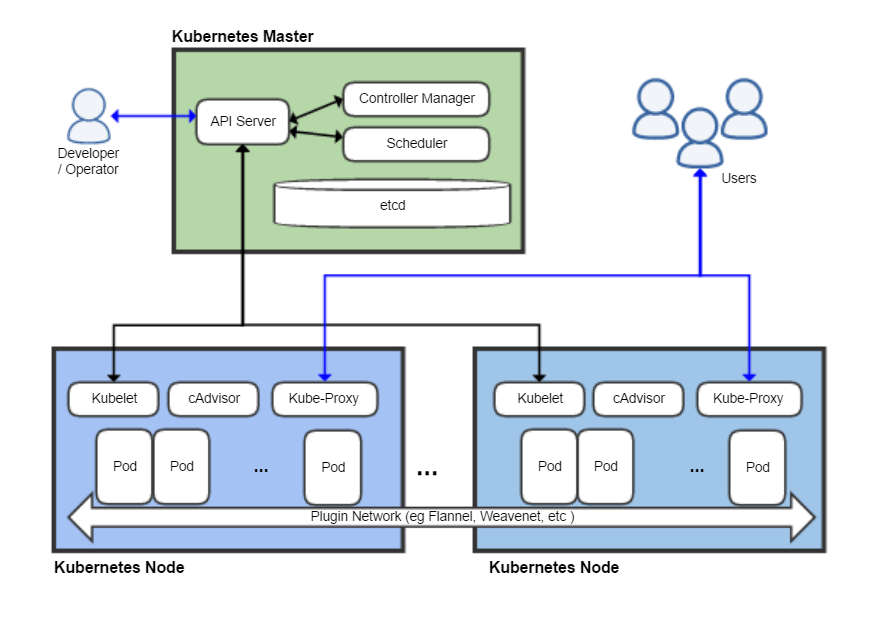
Kubernetes节点按功能可以分为两类:Master和Node。其中Master是集群的管理中心,而Node是承载容器运行的worker。一般情况下,一个集群会有奇数个Master节点和若干个Node节点。当然,一个节点可以即是Master又是Node。
一 etcd
etcd是一个具有高可用性和强一致性的键值存储系统,是Kubernetes中最重要的组件之一。它基于raft算法,高可用性是得益于raft算法的Leader Election机制,而强一致性是因为raft算法的Log Replication机制。不光是Kubernetes,几乎任何一个分布式系统,都需要一个这样的数据同步组件。比如Docker Swarm是自己实现了一个raft算法提供数据同步。
之所以将etcd从Master和Node中抽离出来,是因为它即在Master中作为整个集群节点状态的数据同步组件,又在Node中充当网络插件的网络状态同步组件。
二 Master中的组件架构
Master中主要有Controller Manager,Scheduler,API Server。
2.1 API Server
API Server可以理解为控制和监控集群的入口,它提供了对集群各种资源访问和控制的REST API。
管理员可以通过kubectl或者第三方客户端生成HTTP请求,发送给API Server。或者是集群内部的服务通过API Server对集群进行控制操作(比如dashborad)。
另一方面,集群内部的各种资源,如Pod、Node会定期给API Server发送自身的状态数据。而Master中的Controller Manager和Scheduler也是通过API Server与etcd进行交互,将系统的状态存入etcd数据库或者从etcd中读出系统状态。
还有一个作用,就是后面会提到的,从外部访问集群种服务的一种方式:Proxy API。它将API Server收到的请求转发到某个Node上的kubelet进程。比如:
/api/v1/proxy/namespaces/default/pod/{ pod_name }可以发现,API Server是集群内部各个组件通信的中介,也是外部控制的入口。所以需要完备的安全机制确保集群安全,这一部分后面再总结...
2.2 Controller Manager
Controller Manager相当于整个集群的大脑了,一方面它根据管理员命令管理集群资源,另一方面它根据集群中各组件上报的状态信息确保集群始终处于预期工作状态。
如果对Controller Manager细分的话,又可以分为多个Controller,以下列举8个Controller:
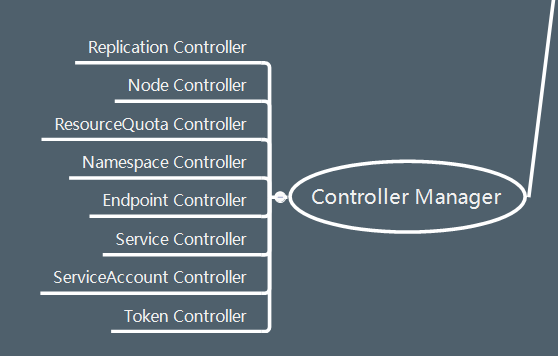
根据名字就大概知道这些Controller的作用了,在这里就不细说了。
2.3 Scheduler
当Controller Manager发出创建新Pod的命令后,Scheduler根据配置的调度算法,在可用的Node里选择一个进行绑定,然后通过etcd和API Service下发给相应的Node。
三 Node中的组件架构
Node中主要有docker engine, kubelet, kube-proxy
3.1 docker engine
这个不用多说,所有的容器最终都是通过docker engine启动的。
3.2 kubelet
每个Node上都会运行一个kubelet,用来从API Service接收master下发的任务和管理运行在自身Node上的Pod。
kubelet通过探针来定期检查容器的健康状态,可以通过exec到容器执行命令、发送一个socket请求或者http请求给容器等。比如在dashborad的yaml中定义的探针:
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
initialDelaySeconds: 30
timeoutSeconds: 30
这里就是定期通过http请求访问容器的8443端口,根据响应是否正常来判断Pod的运行状态。
另外,kubelet还会启动cAdvisor这个开源的分析容器资源使用的工具,对Node进行资源监控。访问http://{{ node_ip }}:4194端口,就可以查看到cAdvisor提供的UI界面。
3.3 kube-proxy
上一篇中提到Service为副本集提供了一个统一的入口,他虚拟出来一个ClusterIP+端口。只需要访问这个地址,就可以访问到副本集提供的服务,而不用关心副本集有多少,他们分布在哪里这些问题。kube-proxy就是Service这个概念背后的实现者。
kube-proxy运行在每一个Node上,从API Service中获取到副本集的ClusterIP和端口,还有副本集中Pod的地址。然后通过向Node节点的iptables添加规则链,把访问转发给相应的Pod。
比如一个nginx-service服务,使用NodePort方式,对外暴露端口,看一看它对应的iptables设置:
root@kube-1:/home/ubuntu# iptables-save |grep nginx-service
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx-service:" -m tcp --dport 20008 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx-service:" -m tcp --dport 20008 -j KUBE-SVC-GKN7Y2BSGW4NJTYL
-A KUBE-SEP-I7AEZWV3OOMOSNST -s 172.20.1.5/32 -m comment --comment "default/nginx-service:" -j KUBE-MARK-MASQ
-A KUBE-SEP-I7AEZWV3OOMOSNST -p tcp -m comment --comment "default/nginx-service:" -m tcp -j DNAT --to-destination 172.20.1.5:80
-A KUBE-SEP-IDBN5YVUGG22YASL -s 172.20.2.4/32 -m comment --comment "default/nginx-service:" -j KUBE-MARK-MASQ
-A KUBE-SEP-IDBN5YVUGG22YASL -p tcp -m comment --comment "default/nginx-service:" -m tcp -j DNAT --to-destination 172.20.2.4:80
-A KUBE-SERVICES -d 10.68.86.206/32 -p tcp -m comment --comment "default/nginx-service: cluster IP" -m tcp --dport 80 -j KUBE-SVC-GKN7Y2BSGW4NJTYL
-A KUBE-SVC-GKN7Y2BSGW4NJTYL -m comment --comment "default/nginx-service:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-I7AEZWV3OOMOSNST
-A KUBE-SVC-GKN7Y2BSGW4NJTYL -m comment --comment "default/nginx-service:" -j KUBE-SEP-IDBN5YVUGG22YASL- nginx-service服务以NodePort方式暴露了20008端口,所以访问该Node的20008端口的tcp请求会被转发到
KUBE-SVC-GKN7Y2BSGW4NJTYL链。 - nginx-service的ClusterIP为10.68.86.206,所以在集群内部访问10.68.86.206:80的tcp请求也会被转发到
KUBE-SVC-GKN7Y2BSGW4NJTYL链。 - nginx-service服务后面的副本集有两个副本,他们的Pod IP分别172.20.1.5和 172.20.2.4,所以
KUBE-SVC-GKN7Y2BSGW4NJTYL链,以50%的概率把请求分别转发到这两个Pod的80端口。
以上,通过这些iptables规则链就把外部和内部对Service的访问转发到了承载服务的Pod上。kube-proxy还通过API Service随时监控着这些Pod的变化,如果增加了副本数量或者Pod IP改变,kube-proxy就对iptables做相应的修改。
写的很好,很详细
写的不错测试一下
lz写的非常好啊